
Every day, hundreds of thousands explore diverse listings on Funda. Passionate about machine learning recommendations, Data Engineer Dylan van Wonderen pitched his thesis at Funda, receiving an enthusiastic response and a job offer. Curious? Read it here.
Last year, I had the opportunity to undertake my master’s thesis at Funda, focusing on a topic that truly captivates me: recommendations using machine learning. From the outset, my goal was to find a company where I could develop a machine learning model for generating personalised recommendations, a pursuit fuelled by my fascination with the profound impact these algorithms have on our online behaviour.
The subject became the cornerstone of my final thesis, and I reached out to Funda's data team to present my idea. Fortunately, they embraced my proposal, providing me with the chance to delve into the realm of personalised recommendations. This marked the beginning of my experimentation with various methods to tailor recommendations specifically for funda users.
Given that hundreds of thousands of users navigate Funda's extensive catalogue every day, using its powerful search functionality, it presented the perfect case to dive in to. This was particularly relevant because industry-leading internet giants enhance user experiences with personalised recommendations. Intrigued to offer a similar approach, Funda generously supported my research, allowing me to explore the feasibility of personalised recommendations for their users.
Why GNNs?
When I pitched my idea to Funda, I had a clear method in mind for generating recommendations. Graph Neural Networks (GNNs) have been used by tech giants to power their recommendation engines, so we wanted to explore this method to power Funda's recommendations.
For example, Uber Eats used GNNs to improve the effectiveness of the personalised dish recommendations. Pinterest used GNNs on an even larger scale, to decide what pins would be shown to users next. Lastly, Amazon has also experimented with GNNs for product recommendations and found this method significantly outperformed other benchmarks. Seeing the effectiveness of GNNs for these industry leaders, I was keen to apply this method to our recommendation problem.
Modelling of the problem
GNNs are adept at learning relationships from data that is represented as a graph to make predictions about the graph. In this context, a graph is a network of connection points and links/connections between the connection points. The points are called the nodes and the connections between the points are called edges. Together, the nodes and edges make up the graph. Many real-world problems can be modelled as graphs.
See also: Machine learning: the model behind Funda's Waardecheck
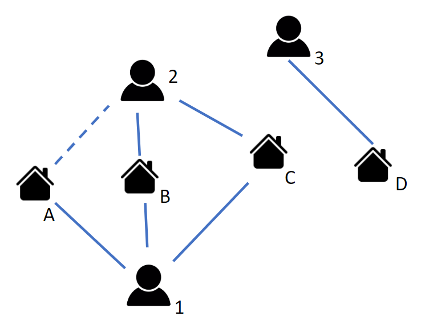
For a recommendation task, the problem must be represented as a graph. The picture below shows a simple, minimal example of a user-house graph. In our case, we create a heterogeneous graph of users and houses as nodes with an edge between the nodes if a user viewed the house. So in the graph, user nodes are connected with house nodes that they showed interest in.
To create personalised recommendations for a user, we need to predict new edges in the graph based on the existing edges. Which is the same as predicting the users' interest. This is where GNNs come in. In the image the predicted edge is the link between user 2 and house A. Since user 2 and user 1 already have two houses in common, it is likely that the third house that user 1 likes will also appeal to user 2.
Applying GNNs
GNNs are utilized to transform the graph structure into embeddings for predictive purposes. A node embedding serves as a mathematical representation of this node, expressed through a vector – essentially, a list of numbers enabling mathematical operations on graph nodes.
The GNN encodes nodes into embeddings to predict edges using the dot product. The dot product between embeddings of two nodes provides a 'relevancy score' for that house to the user. The most pertinent recommendations are then generated by computing relevancy scores for all houses accessible to a user and selecting those with the highest values.
In this blog post, I won't delve fully into the encoding steps of the algorithm, as there are other resources providing detailed information on this. For those interested, my work was inspired by the work of Uber and Pinterest, so reading their blog posts about the method details will help with understanding. I mostly followed the unsupervised approach outlined in the GraphSAGE paper where I used trainable weights for the initial node representations.
Results
The concluding step involves evaluating the effectiveness of the recommendations. I conducted a comparison between GNN recommendations and a baseline to assess their effectiveness. The baseline relied on the price, location and size of the last viewed house to determine the houses the user would view next. The GNN model used the richer viewing history of the user to predict the houses they would view next. The GNN recommendations were seen to be more accurate than the baseline model in offline tests.
Personalised recommendations could significantly enhance the features offered on the Funda website. However, to truly assess their effectiveness, conducting an A/B test with a live user group is imperative. With that test we could measure if users engage more with the GNN recommendation or a baseline recommendation, which would indicate which recommendations are more effective. The scope of my research was limited to only the offline tests of the effectiveness of the model, but who knows, maybe we will test using an online A/B test in the future?
Challenges and future
My work has demonstrated that GNNs can effectively capture and learn user preferences, helping determine other houses that users might find appealing. This capability enables Funda to begin developing features that provide users with a personalised experience based on their preferred houses.
However, my thesis also highlighted some lingering challenges with GNNs. One issue is the lengthy training time required for these algorithms. Fully training a GNN model means waiting for hours in most cases. This significantly hampers the speed of development and the speed at which different versions of the model can be tested.
The second challenge with this method for recommendations is that we require a few interactions from a user during training time before the model can provide effective recommendations. This means that new users, or those not logged in, will receive inaccurate recommendations when such a feature is active on the website.
I hope that the challenges in creating recommendations can be overcome, and we can find a way to introduce personalised recommendations on to the Funda website. For now, I had a great time developing this algorithm for Funda and graduated from my master’s. I even got my first full-time job out of it... at Funda of course 😉.
See also: Decoding Funda's tech stack: the reasons behind our choices
