
Recently, Funda switched to Azure DevOps to build and deploy pipelines. In his article, Software Engineer Tom Freijsen shares how we used composability to allow teams to manage their own pipelines, while preserving some level of consistency across our organisation.

This blog was originally published on February 16, 2023. The content has been reviewed to ensure it's still up to date. Now, let's dig in!
This is the first of a blog series of four about our CI/CD engineering setup. If you are interested in our CI/CD setup, please also read the other blogs in this series. Where Pascal highlights the Backstage developer portal's templates for accelerated integration in the second blog post. In the third post, Kateryna explains about efficient testing practices in our Azure DevOps pipeline. Finally, in the last post, Marek reveals how we streamlined our Azure DevOps experience.
In this blog post about modular pipelines, Tom will show how our historical pipelines were formed, outline the design principles on which we have based our new pipelines, and give an example of what such a pipeline might look like.
Pipelines in Bamboo
Ever since the concept of developers deploying their own code was introduced at Funda, we have been using Atlassian Bamboo for our build and deploy pipelines. This tool allowed our Site Reliability Engineering (SRE) team to define what steps were necessary when updating a website or service on one of our application servers.
At the time it was a big step up from the fortnightly release cycle we used to follow, and it enabled our teams to deliver new features and bug fixes more quickly. Over time, custom tooling was built around Bamboo, such as quality gates and, as the volume of releases grew, a queue to determine who is next in line to deploy our main website.
Migration to Microsoft Azure and Kubernetes
In 2020 we moved our infrastructure from our own on-premise services to Microsoft Azure. Right from the start, we provisioned all our cloud infrastructure using Terraform. This lowered the bar for our teams to start using cloud-native services like Azure Service Bus and Cosmos DB.
Additionally, we moved our containerized applications from DC/OS to Kubernetes and added Helm to configure their deployments right from the repository. Over the past few years, we have also been working to move functionality away from our legacy .NET Framework monoliths into feature-scoped microservices. While four years ago those monoliths were still our most deployed applications, this shift has caused them to be updated less often, while containerized services get deployed significantly more.
Using Flux CD and Helm
To deploy to Kubernetes, we had initially adopted a GitOps flow with Flux CD and Helm. The idea of defining our currently deployed revisions in code sounded simple, yet powerful. In practice, our approach led to several unforeseen problems, stemming from the fact that the Flux operator only looked at the main branch. We had to merge any Helm chart changes to the main branch to test if they worked at all. We also had to commit to the main branch in order to update the current revision on our acceptance environment.
Branch protection rules prevented our developers from making these commits without a pull request, and the flow differed significantly from what they were used to. Therefore, the Bamboo deploy pipelines would commit revision updates to the main branch automatically. This meant half of the commits on main were revision updates. Additionally, when one of these deployments broke, there was no visibility into what had happened. Developers had to reach out to the SRE team, who had the necessary expertise and permissions to resolve such issues.
All in all, our software landscape has changed a lot since we started using Bamboo. When Atlassian announced that Bamboo would reach its end of life in 2024, it gave us an opportunity to rethink what our CI/CD solution could be like in the future. An exploratory survey across all developers showed a preference to host our code in GitHub and run our pipelines on Azure DevOps.
Team independence
In his book Team Topologies Matthew Skelton describes the purpose of a platform team as “enabl[ing] stream-aligned teams to deliver work with substantial autonomy. The stream-aligned team maintains full ownership of building, running, and fixing their application in production. The platform team provides internal services to reduce the cognitive load that would be required from stream-aligned teams to develop these underlying services”.
As Funda’s platform team, it is our responsibility to reduce the cognitive load on the stream-aligned teams, so they can fully concentrate on producing new features. The stream-aligned teams should be able to do their work autonomously, which includes being able to provision infrastructure, deploy services and investigate failed deploys.
In this light, we wanted to give our teams the responsibility for and the ability to change their own pipelines, while not having to spend weeks reinventing the wheel and fighting implementation details. The Platform team could provide a set of templates for developers to use for their applications.
Composable templates
Our goal for these templates was to cover most use cases in our Product Development department, and to make them especially easy to use when following our Golden Paths. At the same time, we realized more complexity leads to more edge cases and more cognitive load, which impacts developer autonomy. Therefore, we decided to create composable and self-contained templates for each possible stage in the pipelines.
Read also: How Golden Paths give our developers more time to actually develop
For example, we have templates to build a Docker image, to run .NET unit tests, to deploy a Helm chart, or to run upgrade tasks. All of these templates have been designed to work together without much extra configuration. This way, developers only have to include and configure the functionality they actually need. An added benefit is that this allows for easy extensibility. When some desired functionality has not been implemented as a template, one could simply add their own stage.
Separation of build and deploy pipelines
We also decided to clearly separate build and deploy pipelines. Azure YAML Pipelines do not have the concept of separate release pipelines. The user is free to implement any pipeline they wish, and in examples across the internet the build and release are often combined. This may work on a small scale, but our experience has shown that there are some drawbacks. When any pipeline run includes the deployment stages, these must be regulated with a ManualValidation task to make sure they do not immediately start after every build.
While the manual validation task is waiting for an approval, Azure DevOps still shows the pipeline as if it is in progress. Most of these pipeline runs will just be CI builds with no intention of ever being deployed. They will be displayed as ‘in progress’ for an hour, after which they will go into a failed state for having ‘failed’ the manual validation. This is confusing and hurts the usability of the Azure Pipelines UI. The issue is exacerbated when there is more than one environment one could deploy to.
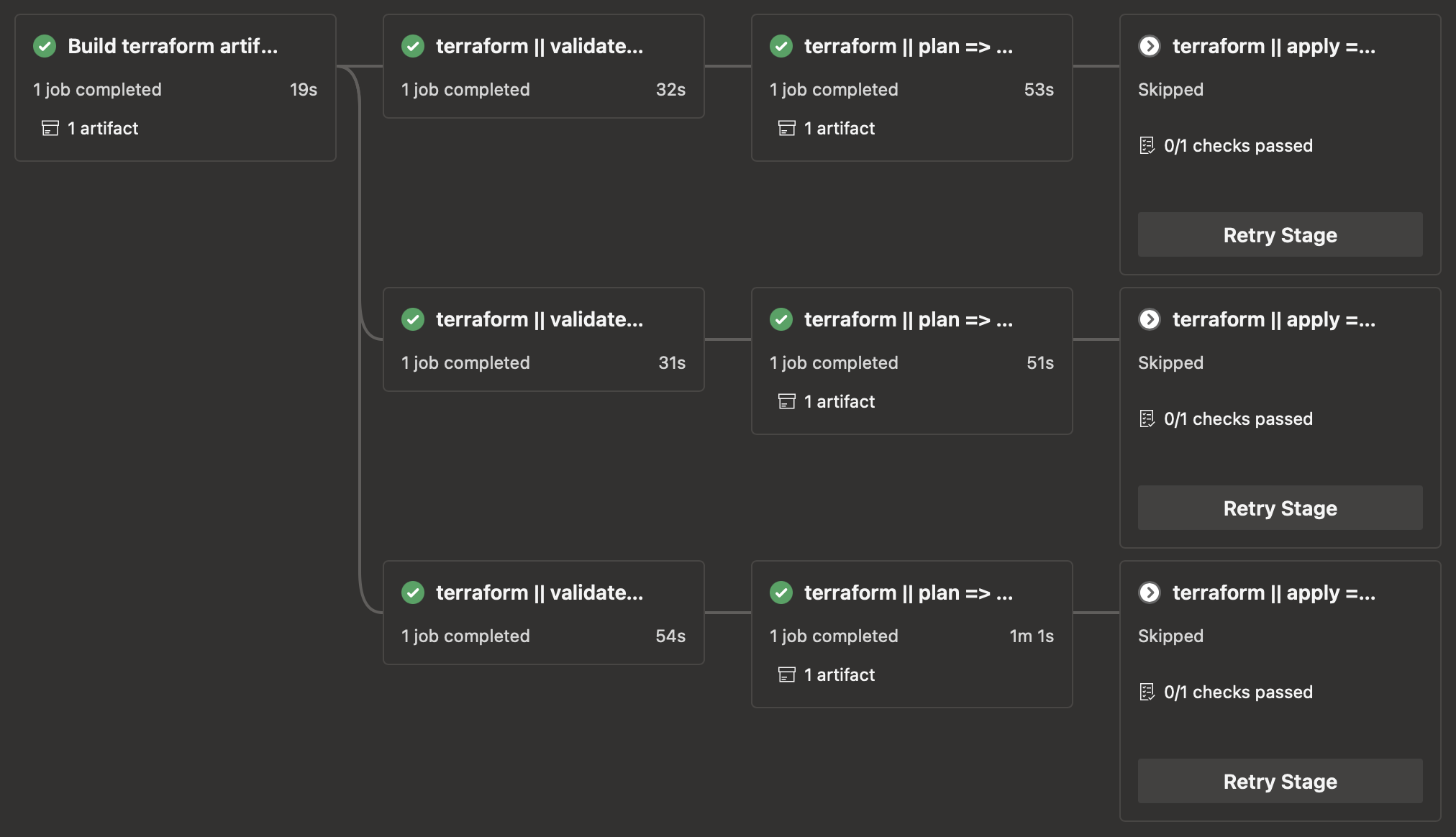
We have several development environments, an acceptance environment, and a production environment. Each of these would need its own deployment stages in the pipeline, which could easily get out of control. Therefore, we chose to make our build pipelines publish Docker images. A deploy pipeline can then deploy those to an environment provided by a pipeline parameter.
To allow our colleagues to easily start a new deploy from a finished build pipeline, we developed an Azure DevOps extension. This displays a list of environments with their current deploy status and can start new deploys to them. In another blog post we will go into this in more detail.
While previously we had separate infrastructure and application deploy pipelines, our new pipelines perform both these tasks. This reduces the cognitive load on our developers, as generally the same commit will have been used for both the code and infrastructure in an environment.
Examples
To illustrate these concepts, let us look at some example pipelines. A pipeline that builds a single .NET service may look as follows:
trigger:
branches:
include:
- "*"
paths:
include:
- "*"
pr: none
resources:
repositories:
- repository: templates
type: github
ref: refs/tags/1.2.0
name: fundarealestate/service-pipeline-templates
endpoint: fundarealestate
stages:
- template: service/build/build.yml@templates
parameters:
name: Build
buildProjects:
- projectName: "Funda.MyApplication"
imageName: myapplication
- template: service/build/unit-tests-dotnet.yml@templates
parameters:
name: UnitTestsDotNet
- template: service/build/validate-terraform.yml@templates
parameters:
name: ValidateTerraform
- template: service/build/show-deploy-ui.yml@templates
parameters:
dependsOn:
- Build
- UnitTestsDotNet
- ValidateTerraform
deployPipelineDefinitionId: 423Trigger
The trigger and pr entries instruct Azure DevOps to run the pipeline for every commit, and ensure that it does not run again when it is part of a pull request. The repository resource adds a reference to our pipeline templates repository, and we use git tags to reference a specific version of the templates.
Linking stages together
For each stage we reference a different template. The name and dependsOn parameters are present in all templates, and allow us to link our stages together. In this case, the ShowDeployUI stage depends on the Build, UnitTestsDotNet and ValidateTerraform stages. Azure DevOps will make sure that these have all succeeded before the Deploy UI is shown.
Stage parameters
Most of these templates have very few required parameters. By choosing sensible defaults that match the conventions within our organization, a developer configuring a new pipeline usually does not have to set up many parameters. This reduces the amount of work required to write or understand the pipelines. However, in some cases the requirements are different, and it makes sense to deviate from the norm. We benefit from being able to use the same templates across Funda, and so we offer customization using parameters when needed.
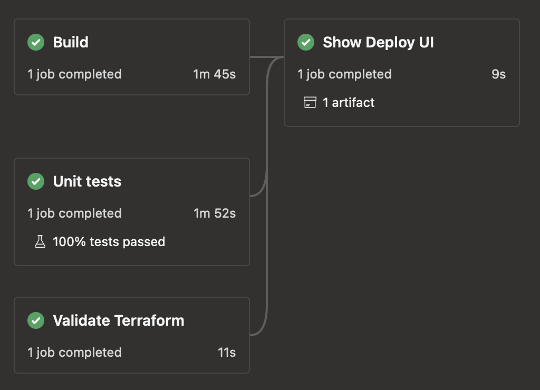
Deploy pipeline
From the Deploy UI, which gets rendered by our custom Azure DevOps extension, a developer may choose to start a deploy pipeline. A simple deploy pipeline would look like this:
trigger: none
pr: none
name: " Deploy to ${{ parameters.environment }}"
parameters:
- name: environment
type: string
- name: imageTag
type: string
resources:
repositories:
- repository: templates
type: github
ref: refs/tags/1.2.0
name: fundarealestate/service-pipeline-templates
endpoint: fundarealestate
stages:
- template: service/deploy/terraform-plan-apply.yml@templates
parameters:
name: TerraformPlanApply
stateKey: my-application
environment: ${{ parameters.environment }}
- template: service/deploy/deploy-helm.yml@templates
parameters:
dependsOn: TerraformPlanApply
releaseName: my-application
environment: ${{ parameters.environment }}
imageTag: ${{ parameters.buildTag }}Since this is a deploy pipeline, we do not want it to automatically get triggered by commits or pull requests. We typically use a custom name for the pipeline runs, that contains the environment to which it deploys. This allows developers to scan the deploy list in the Azure DevOps UI more easily.
The two parameters, environment and imageTag, are provided by the Deploy UI extension that started the pipeline run. environment contains a string referencing the environment, and imageTag contains the tag under which the Docker images have been published in the Build stage of the build pipeline.
Terraform stage
This example contains just two stages, TerraformPlanApply and DeployHelm. The Terraform stage detects whether infrastructure changes have been made, and if so, generates a plan. After getting explicit approval for that plan, it will apply the changes. If no changes have been made, no approval is necessary and most of this stage will be skipped to save time.
Helm deploy stage
The Helm deploy stage works in a similar way, only requiring explicit approval when significant changes are detected. Other than that, it will automatically fetch an application’s Azure Managed Identity details, will perform an automatic rollback if the task fails or gets cancelled, and has been designed to integrate with the Helm charts we typically use at Funda.
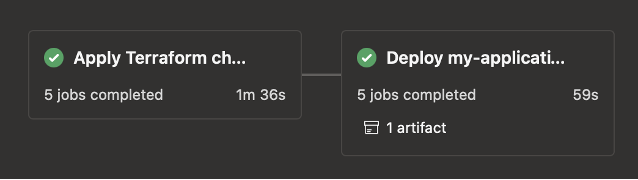
These pipelines could be extended with stages based on our templates for NPM unit tests, integration tests, upgrade tasks, Playwright tests, publishing documentation to Backstage, and more.
Where we will go from here
While Bamboo allowed us to dramatically increase our deployment frequency, our cloud migration and our efforts to make teams more autonomous caused us to run into its limits. Flux CD fulfilled a role in our move to Azure and Kubernetes by mostly decoupling Helm deploys from Bamboo, but in the end it turned out to have unforeseen downsides and be unintuitive for developers.
This triggered our move to Azure DevOps – but without good pipelines, that might have resulted in similar difficulties. By providing composable and easy-to-use stage templates however, we have made Azure DevOps a more accessible and powerful tool for Funda's developers. Because these templates reduce stream-aligned teams’ cognitive load, more of their development capacity can be directed towards building new features.
In the future, we will continue to improve our templates based on feedback and changing requirements. For instance, there has recently been an additional project to overhaul our Helm charts, so that they are more maintainable and easier to use.
See also: Embracing remote Helm charts and Library charts
Question?
Do you have a burning question for Tom after reading this blog? Feel free to reach out to him via email.
See also the other articles from the Platform Team:
Blog 2: How to accelerate CI/CD integration with Backstage software templates
Blog 3: Running Playwright tests in Azure DevOps: A step-by-step guide
Blog 4: Streamlining the Azure DevOps experience