
DevOps Engineer Matt Bennett, with 5 years of Terraform experience, shares vital lessons he wished he learned earlier. Seize this opportunity to enhance your Terraform approach and enrich your experience by reading his blogpost.
What is Terraform?
Firstly, to provide some context, Terraform is a tool developed by Hashicorp which allows you to automate the provisioning of cloud infrastructure. To help describe it I would like to give a short example:
resource "azurerm_resource_group" "my_resource_group" {
name = "rg-my-group"
location = "westeurope"
tags = {
owner = "matt@funda.nl"
team = "SRE"
app = "my-app"
}
}In this very simple example we created a single resource group, which is just meant for grouping other resources in Azure.
The Terraform Model
Unlike a lot of common programming languages, which are imperative, Terraform is a declarative language. This means that you specify what you want, but not how to do it. This can take a bit of getting used to at first.
Once you are accustomed to writing Terraform there is also the conceptual model of how it works. I like to think of it as having three “sources”. The first source is the code, which is what you have written in your .tf files. The second source is “state”; later on, we will dive deeper into this, but for now you can think of it as what the infrastructure looked like when the last apply finished. The third source is “reality”, which is how things actually are in the cloud provider.
The Terraform workflow
The major commands you will use when starting out with Terraform are:
$ terraform init
$ terraform plan
$ terraform applyThe init command is a little complicated so we will cover that one later. The plan command is what you run to see what changes Terraform wants to make. To calculate these, Terraform inspects the three sources I mentioned earlier, and takes action based on whether they are in sync or not.
The simplest case is when there are no differences in the three sources; then there are no changes required and Terraform will report that. However, since we more often than not run Terraform to achieve specific goals, you will usually encounter the following situation:
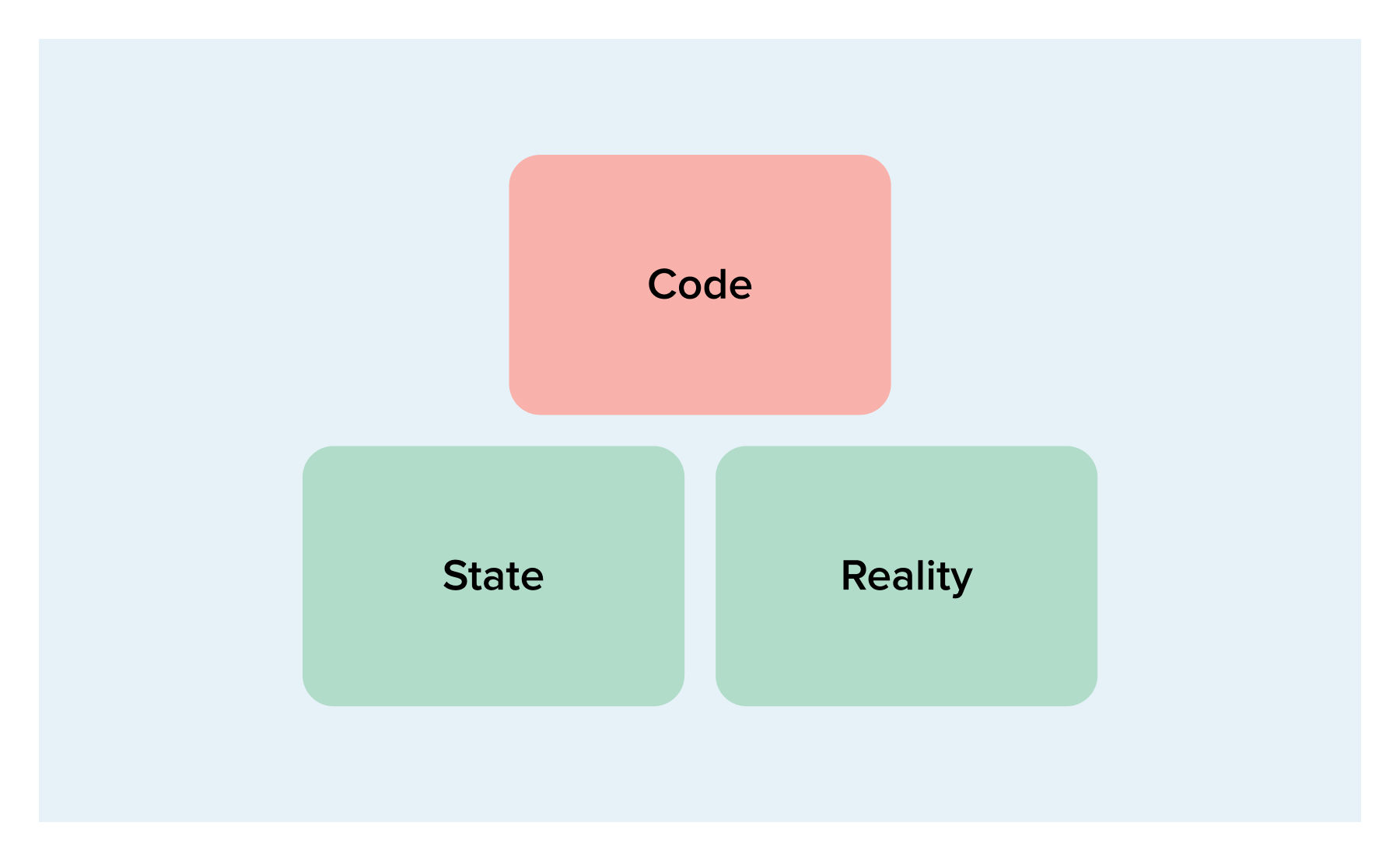
So state and reality match up, but not code. This means you have made a change in the code, probably to add a new resource or something. The plan will add the resource you added to the code.
The next scenario may arise due to manual interference:
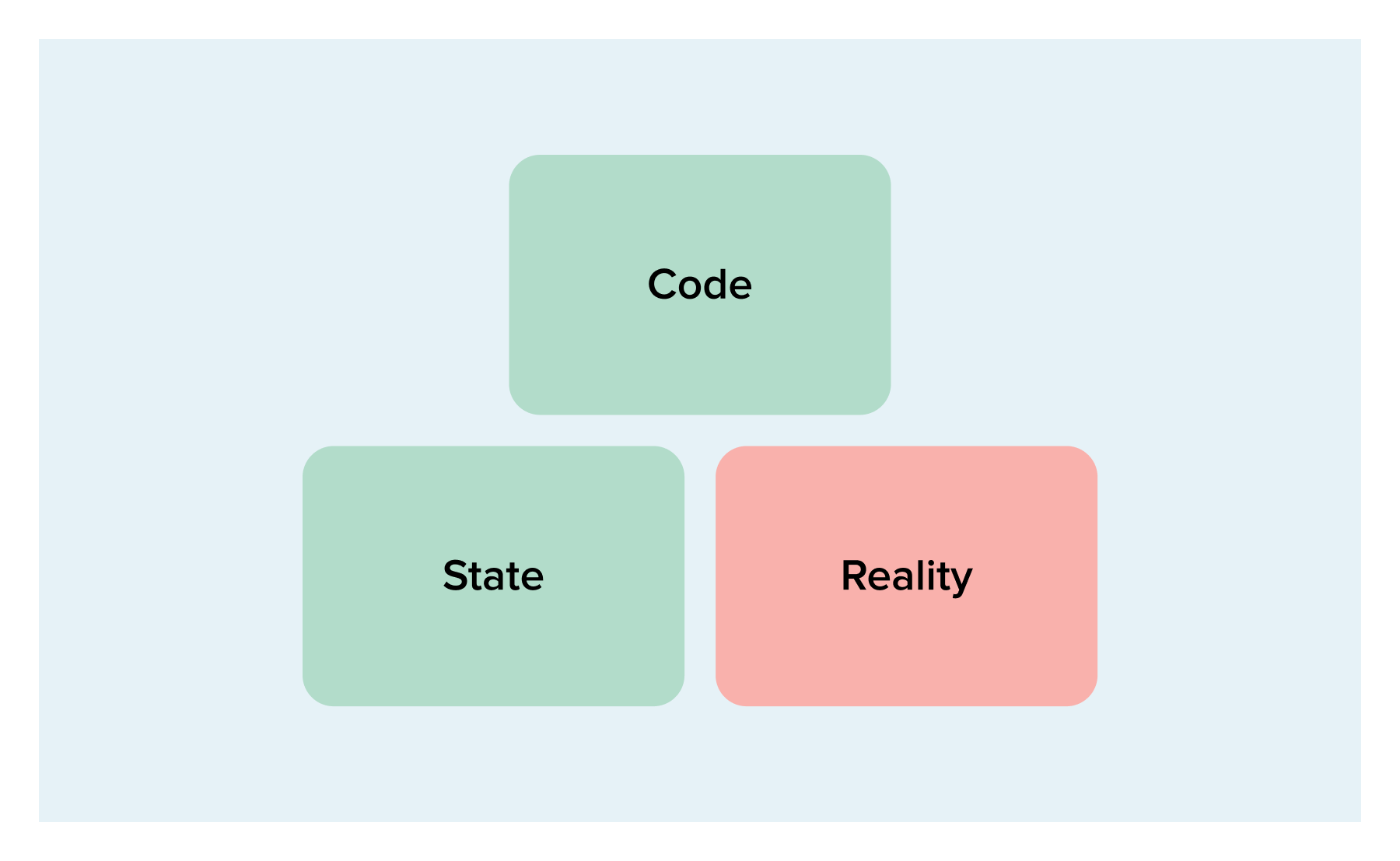
Code and state are in agreement, but in reality, something is different. This means that someone has likely made a manual change in the cloud provider and Terraform is trying to revert that. You should be careful when applying this plan as the change that was made might actually be intentional. If that is the case you need to change your code to match.
LESSON: When using Terraform to manage your infrastructure, avoid manual changes as much as possible and make them in Terraform instead.
The next case is what might occur after you’ve changed the code:
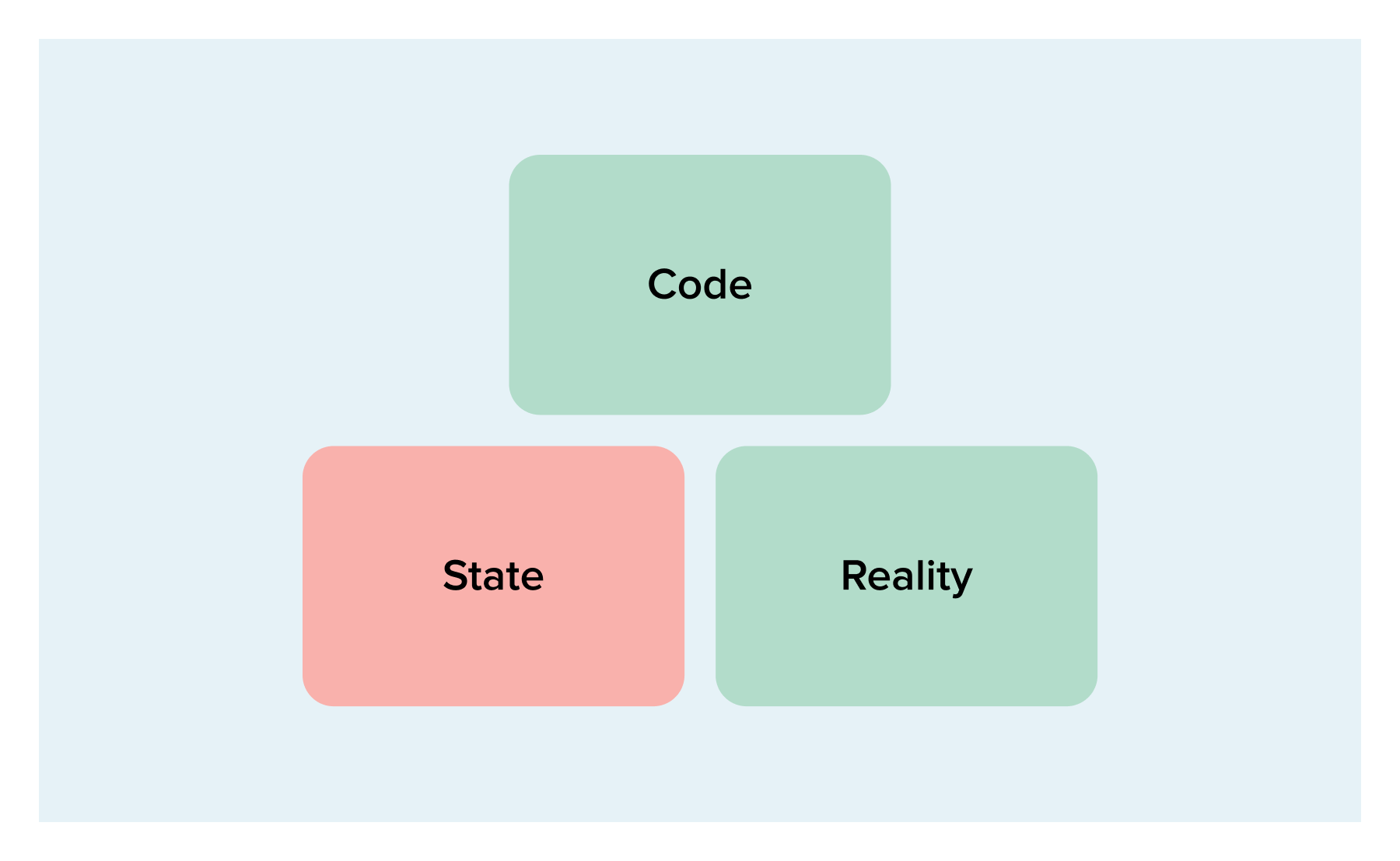
So now code and reality agree, but state is still out of sync. In this case the plan will make no changes but will update state to match the other two sources.
The final case I would like to cover is when things get really messy:
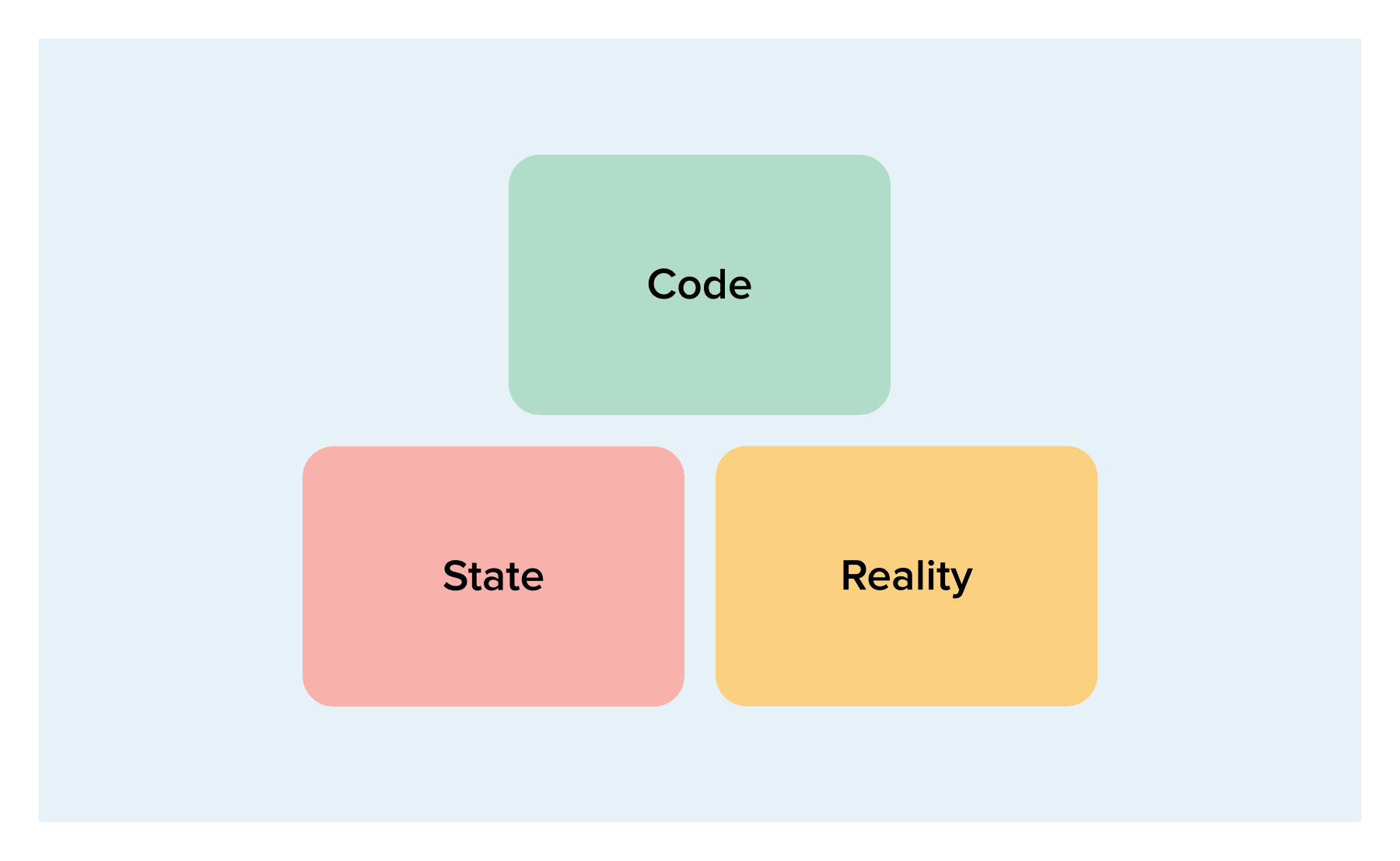
Here, all three sources disagree with each other, so it is likely you have made a change in the code and also a manual change in the cloud provider. The specifics vary, but in general the plan which Terraform generates will try to bring reality in line with code and update state to match.
Now that we know how the plan command works, the apply command is pretty simple. If you give it a plan generated earlier, it will carry out that plan. If you don’t give it one then it will generate a plan itself, using the same logic as before, and run it after giving you a chance to inspect it. The last thing Terraform does when running apply is to update.
What is state?
State is a very important concept in Terraform, and it’s one which I did not completely understand at first. This led to some bad situations as I tried to work around my lack of knowledge – such as losing all the infrastructure for my application and accidentally overwriting one state for another, leading Terraform to repeatedly attempt to recreate the resources.
In the simplest terms, you can think of state as Terraform’s “memory”. When Terraform creates a resource, it automatically writes the resource details into state. Likewise, when a resource is changed, state is updated to reflect the change. Without state, Terraform would not know which resources it was in charge of across the whole cloud provider. If you add a resource to a cloud provider manually, it will not be in state and you will need to import it (more on that later).
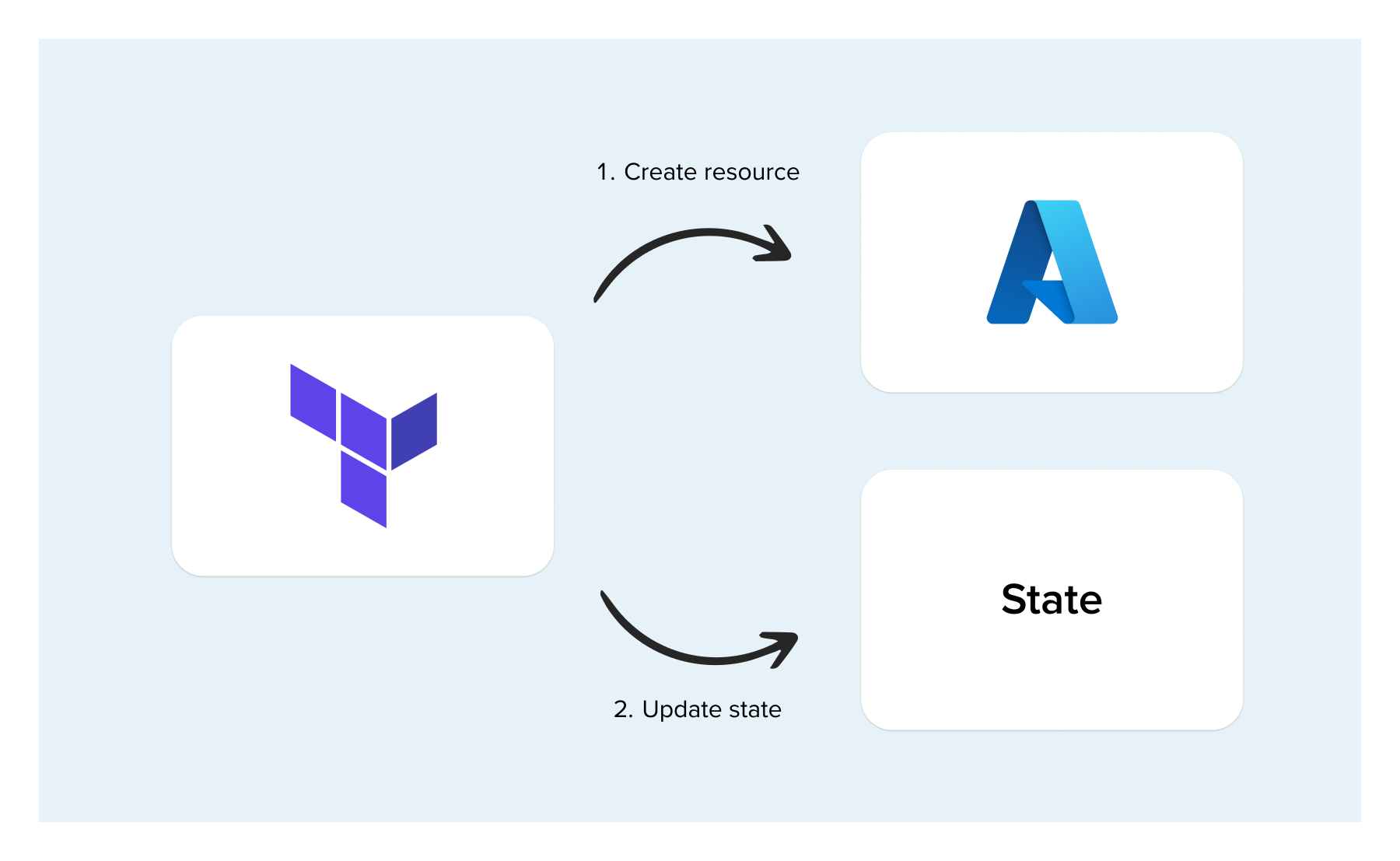
Where is state?
The actual implementation of state is a large JSON file containing all the relevant data. This file needs somewhere to be stored. The default is to have a “local” state. In this case the state is in a file next to the Terraform config called “Terraform.tfstate”. A local state comes with a lot of disadvantages so I would recommend avoiding this, except for in the simplest of cases. So where else can you store it instead?
This is where a “remote” state comes in. Terraform has adapters for most large cloud providers so you can store state in an object store (think S3, or Azure Blob Storage). This is better than storing state locally because it means you can keep automatic backups/versioning and you can have multiple developers working on it by sharing a state file that isn’t just on their local computer.
LESSON: Always use a remote state rather than a local state.
When sharing a state file in this way, a remote state also provides a nice feature called state-locking. State-locking is supported by most remote providers, including AWS, Azure and GCP. A local state cannot support this because there is no possibility to co-ordinate between different runs. When running, Terraform puts a lock on state so that other processes cannot run at the same time and potentially cause inconsistencies.
Read also: Running Playwright tests in Azure DevOps: A step-by-step guide
What are providers?
Another new concept to learn about when starting with Terraform is providers. A Terraform provider is what allows Terraform to interface with cloud services. For example, in the code snippet at the beginning of this post, I used the “azurerm” provider to create resources in Azure. There are providers for almost any common cloud service you can think of, including Azure, AWS, GCP and even Kubernetes. The reason there are so many is that there is a flexible framework, enabling anyone to develop their own custom providers.
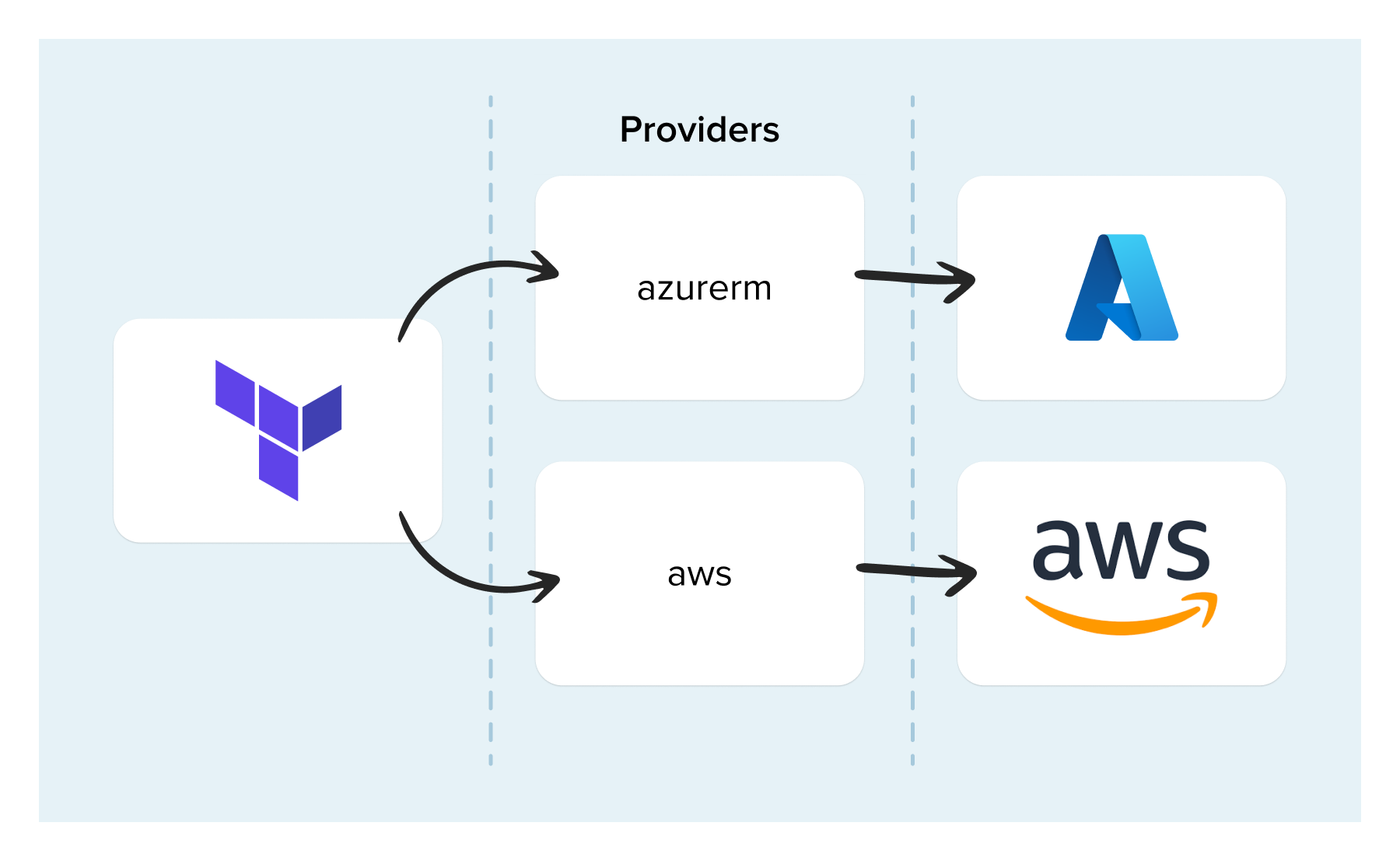
Providers define a set of “resources” which you can create. Each of these resources maps to a real type of resource in the cloud service they interface. Like any good piece of software, providers are versioned according to Semantic Versioning. Versioning providers like this helps you understand the implications of an upgrade much better. So, when using them, you will be informed of any changes that are likely to affect you.
LESSON: Pay attention to breaking changes, i.e. “major” version bumps.
What are (child) modules?
Modules are something that I also got wrong when first learning Terraform because I tried to use them too early and wrote some modules which were not very good. This led to me discounting them entirely when in fact they can be very useful. The first piece of advice I would give is to leave them alone for a little while until you are a bit more comfortable with Terraform in general. But after that you can follow my tips below.
Firstly, the term “module” technically refers to any set of Terraform files, but when I mention it in this post I am referring to the concept of “shared” or “child” modules. To give an example of what modules are capable of, consider the following Terraform code:
module "my_vnet_module" {
source = "Azure/vnet/azurerm"
version = "4.0.0"
resource_group_name = "rg-my-group"
use_foreach = false
vnet_location = "westeurope"
}You name the module using the “module” keyword. The “source” argument tells Terraform where to find the module. A child module is a pre-packed set of Terraform config, which can abstract away the complicated details of a specific solution you are trying to deploy. In the example above, the "my_vnet_module" might expand out into something like this (with the details of the resources left in the “…” for simplicity):
resource "azurerm_virtual_network" "vnet" {
...
}
resource "azurerm_subnet" "subnet" {
...
}
resource "azurerm_subnet_network_security_group_association" "subnet" {
...
}
resource "azurerm_subnet_route_table_association" "subnet" {
...
}The resources created by the module can be customized by using the input variables such as “resource_group_name”, “use_foreach” and “vnet_location”.
Modules can help you avoid repetition in your Terraform code. If you are making the same resource in a similar way multiple times you can put it in a module and you only have to write it out once. They are especially attractive to platform teams since they can be provided to other teams as a way of standardising infrastructure deployments across the whole company. Teams will be consuming the same cloud services in the same way, which should drastically reduce complexity for teams who manage the cloud service.
However, they do have some tricky aspects. If a specific set of Terraform includes numerous links to upstream modules, it can make it harder to comprehend what exactly is being executed. This is why I recommend really understanding how you want to use Terraform before fully embracing them. When starting to use them, consider the following do’s and don'ts:
- DON'T use child modules within child modules.
- DO create child modules which are simple building blocks.
- DON'T configure providers from within child modules.
- DO treat modules as products, with a versioning strategy and lots of documentation/examples.
What is the “init” command?
With a little more knowledge of Terraform under our belt we can finally talk about the “init” command, as I promised earlier. This command scans your config and gets everything set up for the plan. It resolves the child-module versions and downloads these locally, it connects to the backend so that the remote state is able to work, and it resolves the provider versions and downloads these as well. Note that for provider versions it also creates a version lockfile, which you can use to ensure consistent provider version resolution.
What do I wish I had known when I started?
In conclusion: Terraform is an incredible tool, but you have to work with it in the right way. This can take some time; it took me a couple of years of using it to feel like I understood it and even after 5+ years I am still learning new and better ways of using Terraform. The main aspects I wish I had known when I started are around effective ways of working with it:
- The Terraform model is different to most traditional programming languages.
- In Terraform, you can think of a model as an attempt to bring the three sources into sync with each other.
- Terraform's state acts as its memory, enabling it to track and manage resources amidst a potential sea of cloud resources.
- Providers let Terraform interact with cloud services (or anything with an API).
- Modules can be a bit advanced for those who are just starting out, but they are a really good way to scale up your organisation’s Terraform usage.
Read also: Embracing remote Helm charts and Library charts
