
At funda, Team Search completely rebuilt the search feature, using technologies like Nuxt, Flutter and OpenSearch. Software engineer Anna Huseinova shares insights on utilizing OpenSearch's percolation feature for saved searches in this post. Explore the lessons learned from this upgrade.

Last year, our Team Search embraced the challenge of changing the saved search feature, and I was excited to contribute as a Backend Engineer. In an earlier post, my colleague Marcela shared the story of designing multiple saved search features post-technology migration. Now, I'll dive into the details of the latter part of this journey.
What is the saved search feature?
On funda, you have the opportunity to search for your dream house using a wide array of filters, ensuring your search criteria are as precise as possible. However, for active users, continually selecting these filters on each visit to the site can become tiresome.
That's where the saved search feature comes in handy. With this feature, you can save your customized search criteria and access the results with just a single click. Moreover, you can opt to receive notifications via email or push notifications for new listings that match your criteria. In essence, the saved search feature streamlines your house-hunting experience, saving you time and effort.
More than 1,000,000 of our users have already embraced it. Among them, over 600,000 have activated email notifications, while over 400,000 have opted for push notifications. We're currently processing over 4 million matches every day and sending out over 200,000 emails daily to notify users about their matches.
Why the need to rebuild the feature?
Last year, we completely rebuilt the feature. One of the reasons for this was to modernize the tech stack used for saved search implementation. We aimed to decouple services responsible for saved searches from services responsible for other features, leveraging the benefits of the cloud and enhancing team independence. The idea was to develop a new implementation utilizing Nuxt, Vue.js, Flutter, .NET, OpenSearch, Azure, Kubernetes and Iterable.
By using these new technologies, we were able to simplify the implementation process. For instance, utilizing the OpenSearch search engine with its percolation feature enabled us to identify matches between newly published houses and registered saved searches. This eliminated the need to maintain our custom-built reverse index and matching logic.
See also: Game changer: the benefits of having a lighthouse architecture
So, what exactly is percolation and how do saved searches function now?
Percolation operates in contrast to the typical search flow. In a traditional flow, you store documents in the index and then execute queries on that index to address questions such as 'which documents satisfy specific criteria'. For funda, the standard search flow involves maintaining the index with houses and executing queries based on selected filters on the user interface, e.g. to find houses for sale in Amsterdam that were published within the last 24 hours.
In the percolation flow, the process is inverted: queries are stored, and a percolate query containing a document is used to determine which queries match the document. For funda, we maintain the index with saved searches. Each saved search document contains a field storing the query based on selected filters on the user interface. Thereafter, percolate queries are executed with newly published houses to identify matching saved searches.
Our saved search implementation operates as follows:
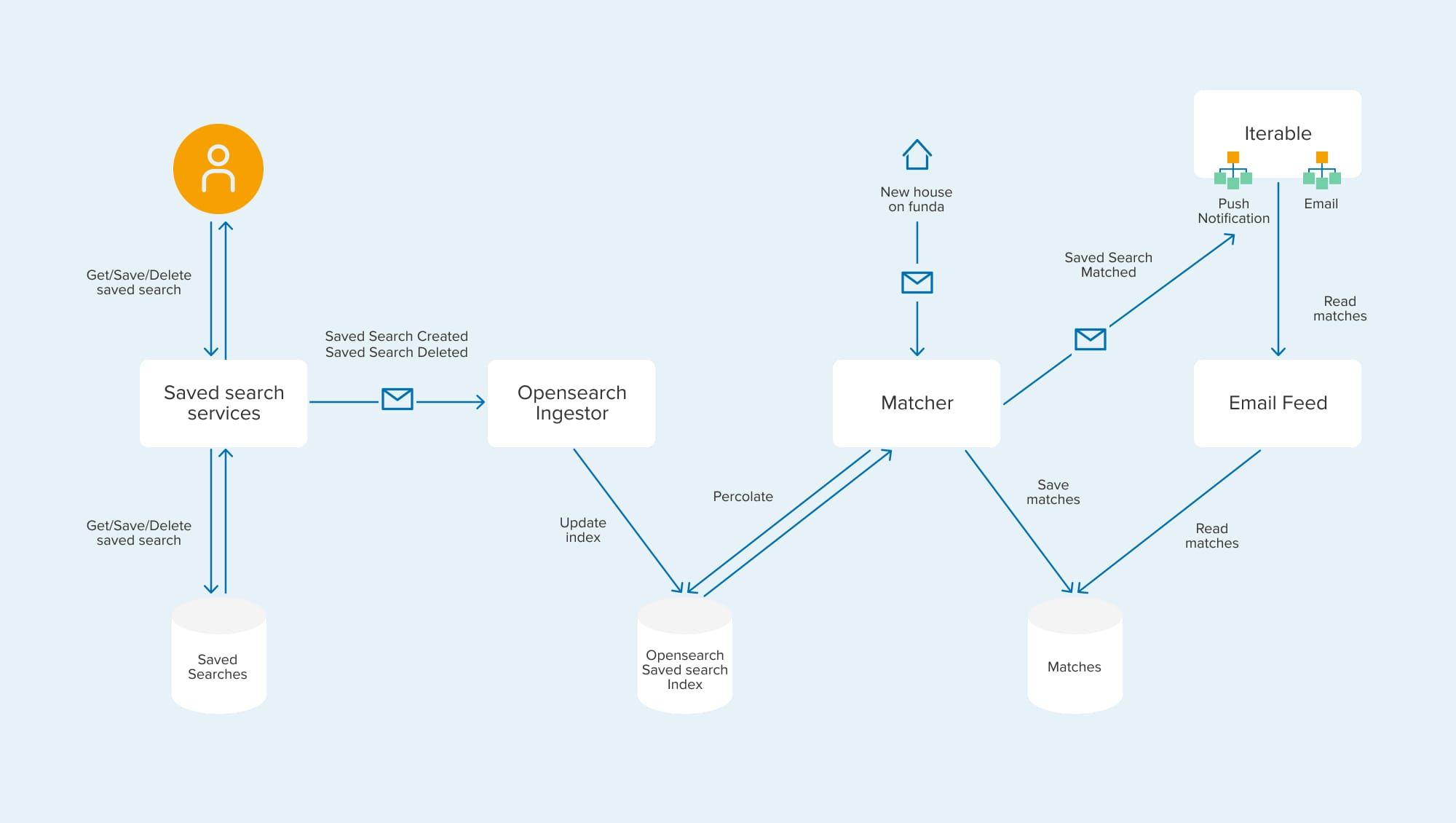
When users interact with saved searches through the web or mobile interface, the changes are recorded in an SQL database and then forwarded to an ingestor service via a message broker.
Let me break down the roles of the ingestor service, the matcher service, and Iterable:
- The ingestor service is tasked with maintaining the OpenSearch index containing saved searches. It is able to keep this index up to date and rebuild it.
- The matcher service monitors events related to new house listings. It uses a saved search index to execute percolate queries. Matches identified by the matcher service are stored in a NoSQL database. This enhances throughput and scalability for the email sending process, especially when dealing with a large volume of emails within a reasonable timeframe.
- Iterable serves as a platform for sending both email and push notifications. A push notification workflow is initiated whenever Iterable receives an event from the matcher service regarding a new match. Meanwhile, an email workflow is scheduled to run once a day, utilizing an email feed to read previously matched houses.
Benefits of the approach
Percolation is designed for efficient document-query matching. Besides, with this approach, the calculation of results is spread throughout the day. This helps to reduce the server load compared to re-running complex queries for every saved search.
Another benefit is that results are already precalculated by the time the emails need to be sent out. We only require relatively not-expensive queries of reading matches by partition key when sending the emails. This improves the throughput and scalability of the service, which is important since we already have over 1 million saved searches – and the number keeps growing.
The approach allows for a unified implementation responsible for finding matches, regardless of a user's chosen notification method: email or push notifications. This avoids code duplication and reduces complexity.
Challenges of this approach
While percolation is well-suited for implementing saved searches, there are a few things to bear in mind.
For emails, an additional storage component is necessary to store the matches. Given that this data grows rapidly and becomes obsolete quickly, continuous clean-up is essential. Fortunately, many cloud storage providers now offer options to configure retention policies, mitigating this issue in most cases.
The approach also introduces challenges in handling cases where a user updates a saved search. In such instances, additional logic is required to ensure that the user does not receive matches that were stored before the update and are no longer relevant to their updated saved search.
To address this, we've implemented a solution by making saved search queries immutable. This means that whenever a user updates the filters for a saved search, we delete the existing search and create a new one. As a result, the previous saved search ID is no longer associated with the user's account, and its matches will not be included in their email feed. We do not delete those matches immediately, since we have retention policies configured and they will be automatically deleted anyway.
The percolation feature necessitates that the mappings from the document index (in our case, the index with houses) are also present in the percolate index. Consequently, adding a new filter requires not only a reindexing of the document index but also a reindexing of saved searches.
Lessons learned
When considering a percolation workload, it's worth thinking about provisioning a separate cluster. While every use case varies, and maintaining an additional cluster has its drawbacks, if there's another critical workload utilizing the OpenSearch cluster, the investment may prove worthwhile. This strategy helps prevent workloads from competing for resources, ensuring smoother operations overall.
We've opted to maintain two separate OpenSearch clusters: one for regular searches and another for saved searches. These workloads differ significantly in their requirements. The regular search cluster faces consistently high loads throughout the day, and it is very important that it remains stable and fast. The saved search cluster ebbs and flows more, because it is triggered by newly published houses. Since it works in the background, latency is also less important than in the normal search page.
Reduce the number of queries
I highly recommend utilizing filters to reduce the number of queries evaluated during the percolation of a document. Choose a field with high cardinality that exists in both the search query and the document, and incorporate it into saved searches during indexing. Then, include a filter for that field in the OpenSearch query used for percolating a document.
For instance, in our case, where each saved search targets a specific area in the Netherlands and each house is located in a specific area, we leverage location as a filter to exclude saved searches that do not target the area where the house is located. This approach ensures that the percolation query is executed over a reduced set of saved searches, thereby improving latency.
Additionally, try to avoid situations where every document matches a large number of saved searches. This scenario often arises when numerous queries lack any filters, thereby increasing computational load and potentially leading to performance issues. One solution is to impose a requirement for a minimum number of filters for each saved search.
And finally, try to keep percolator queries as simple as possible. If it is possible to do computations at ingestion time to simplify the query, then this approach can significantly enhance performance and streamline operations.
Conclusion
Undoubtedly, it was quite a lot of work to completely rebuild the feature, but unquestionably worth the effort. I was very excited about utilizing the latest technology to implement saved searches. Not only have we future-proofed the implementation by embracing this cutting-edge technology, thus enhancing the throughput and scalability of our services, but we have already experienced the benefits. Our ability to quickly re-iterate the implementation and successfully deliver multiple saved search features underscore the tangible advantages of our endeavours.
See also: Decoding funda's tech stack: the reasons behind our choices
Question?
Do you have a burning question for Anna after reading this blog? Feel free to reach out to her via email.